Security Architecture
Virtual Filesystem
Cryptomator provides a virtual drive. Add, edit, remove files as you're used to with just any disk drive.
Files are transparently en- and decrypted. There are no unencrypted copies on your hard disk drive. With every access on your files inside the virtual drive, Cryptomator will en- and decrypt these files on-the-fly.
Currently WinFsp (on Windows) and macFUSE (on macOS) and FUSE (Linux) are our frontends of choice. If they're not available on your system, Cryptomator will fall back on WebDAV, as it is supported on every major operating system. WebDAV is an HTTP-based protocol and Cryptomator acts as a WebDAV server accepting so-called loopback connections on your local machine only.
Whenever your file manager accesses files through this virtual drive, Cryptomator will process this request via the following layers.
Vault Configuration
Every vault must have a vault configuration file named vault.cryptomator in the root directory of the vault.
It is a JWT containing basic information about the vault and specification what key to use.
The JWT is signed using the 512 bit raw masterkey.
This is an example of an encoded vault configuration file:
eyJraWQiOiJtYXN0ZXJrZXlmaWxlOm1hc3RlcmtleS5jcnlwdG9tYXRvciIsInR5cCI6IkpXVCIsImFsZyI6IkhTMjU2In0.eyJmb3JtYXQiOjgsInNob3J0ZW5pbmdUaHJlc2hvbGQiOjIyMCwianRpIjoiY2U5NzZmN2EtN2I5Mi00Y2MwLWI0YzEtYzc0YTZhYTE3Y2Y1IiwiY2lwaGVyQ29tYm8iOiJTSVZfQ1RSTUFDIn0.IJlu4dHb3fqB2fAk9lf8G8zyEXc7OLB-5m9aNxOEXIQ
The decoded header:
{
"kid": "masterkeyfile:masterkey.cryptomator", /* URI of where to get the key */
"typ": "JWT",
"alg": "HS256" /* current implementations also support HS384 and HS512 */
}
The decoded payload:
{
"format": 8, /* vault format for checking software compatibility */
"shorteningThreshold": 220, /* how many characters in ciphertext filenames before shortening */
"jti": "ce976f7a-7b92-4cc0-b4c1-c74a6aa17cf5", /* random UUID to uniquely identify the vault */
"cipherCombo": "SIV_GCM" /* mode of operation for the block cipher. Other possible values are "SIV_CTRMAC" */
}
When opening a vault, the following steps have to be followed:
- Decode
vault.cryptomatorwithout verification. - Read
kidheader and, depending on its value, retrieve the masterkey from the specified location. - Verify the JWT signature using the concatenation of encryption masterkey and MAC masterkey.
- Make sure
formatandcipherComboare supported.
Masterkey
Each vault has its own 256 bit encryption as well as MAC masterkey used for encryption of file specific keys and file authentication, respectively.
All key material is generated by a CSPRNG (Cryptographically secure pseudorandom number generator).
- In Java (Desktop, Android App), we use SecureRandom with SHA1PRNG, seeded with 440 bits from
SecureRandom.getInstanceStrong(). - In Javascript (Cryptomator Hub), we rely on crypto.subtle.generateKey().
- In Swift (iOS App), we use SecRandomCopyBytes with
kSecRandomDefault.
These keys are themselves protected and can be retrieved using, either of the following methods, depending on the use case:
Using Cryptomator Hub
When using Cryptomator Hub, the encrypted raw masterkey can be retrieved from a the server component.
If a vault is managed by Cryptomator Hub, the vault.cryptomator's kid field will point to the resource URI of said vault on the corresponding Hub instance, prefixed by hub+.
Example: "kid": "hub+https://hub.example.com/api/vaults/bb36d67c"
Every Cryptomator Hub user who is authorized to access this vault will retrieve an individual ciphertext from the vault's /access-token sub-resource.
This ciphertext is formatted as a JWE and can be decrypted using ECDH-ES and the user's static private key.
The JWE's decoded header looks something like this:
{
"alg": "ECDH-ES",
"enc": "A256GCM",
"epk": {
"crv": "P-384",
"kty": "EC",
"x": "p1J...g",
"y": "8Il...H"
}
"apu": "",
"apv": ""
}
The JWE's decrypted payload holds a single value, which can then be consumed by Cryptomator to unlock the vault:
{
"key": "H7u...o==" /* 512 bit raw masterkey */
}
Masterkey File
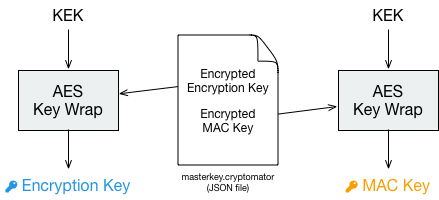
Alternatively, for normal password-protected vaults, Cryptomator will derive a 32byte long KEK (Key-encryption key) via scrypt (non-parallel), encrypt both masterkeys using AES Key Wrap (RFC 3394), and store the results together with the key derivation parameters in a JSON file:
encryptionMasterKey := createRandomBytes(32)
macMasterKey := createRandomBytes(32)
kek := scrypt(password, scryptSalt, scryptCostParam, scryptBlockSize)
wrappedEncryptionMasterKey := aesKeyWrap(encryptionMasterKey, kek)
wrappedMacMasterKey := aesKeyWrap(macMasterKey, kek)

The wrapped keys and the parameters needed to derive the KEK are then stored as integers or Base64-encoded strings in a JSON file named masterkey.cryptomator, which is located in the root directory of the vault.
{
"version": 999, /* deprecated, vault format is now specified in the vault configuration */
"scryptSalt": "QGk...jY=",
"scryptCostParam": 32768,
"scryptBlockSize": 8,
"primaryMasterKey": "QDi...Q==", /* wrappedEncryptionMasterKey */
"hmacMasterKey": "L83...Q==", /* wrappedMacMasterKey */
"versionMac": "3/U...9Q=" /* HMAC-256 of vault version to prevent undetected downgrade attacks */
}
When calculating the versionMac, the version value must be converted to a 32-bit unsigned integer and then encoded as a 4-byte big-endian representation before computing the HMAC-SHA256, regardless of the system's native byte order.
When unlocking a vault the KEK is used to unwrap (i.e. decrypt) the stored masterkeys.